
Implémenter des rolling updates dans Amazon ECS sans CodeDeploy
Contenu
1 Introduction
J’ai rédigé cet article afin de partager mon expérience sur la mise en œuvre de déploiement sans interruption de services au sein de microservices exécutés dans Amazon Elastic Container Service, ECS pour les intimes.
Comme son nom le laisse supposer, ECS est un service d’orchestration de conteneurs qui prend en charge les conteneurs Docker.
Dans cet article, nous allons donc en apprendre plus sur le fonctionnement d’Amazon ECS et voir une solution n’ayant pas recours à CodeDeploy et permettant d’effectuer la mise à jour par lots d’un cluster ECS afin d’éviter les interruptions de service pendant que la modification est propagée. Ce type de mise à jour est connu sous le doux anglicisme de « rolling update ».
Alors je vous vois venir : Mais pourquoi diable perdre son temps à développer une solution (quoique sexy) pour implémenter une fonctionnalité déjà proposée par la plate-forme et gratuitement qui plus est ? Hein ?
La réponse est simple : l’amour du code et de la technique. N’est-ce-pas évident ?
Plus sérieusement, cela peut s’avérer utile lorsque l’on est confronté à un contexte où CodeDeploy n’est pas utilisable (non-conformité avec la politique de l’architecture par exemple). J’espère donc que cet article pourra donc aider ceux qui pourraient être confrontés à ce type de contexte.
Mais en dehors de ce genre de cas de figure, lorsque rien ne vous en empêche, je ne saurais que trop vous recommander d’utiliser CodeDeploy tant l’outil est pratique.
2 Contexte
Prenons donc une application architecturée en microservices s’exécutant dans une machine virtuelle Java (JVM). Nous avons donc des contraintes en termes de mémoire, la fameuse Java heap size et son délicieux « Cannot allocate memory » ou encore « java.lang.OutOfMemoryError ». Que du bonheur, diront certains !
Je reviendrai au travers d’un autre billet sur l’allocation de la mémoire aux conteneurs et sur la manière dont il influence le cluster.
Nos pipelines de déploiement tournent sur une plate-forme SCM et CI/CD. Les pipelines de déploiement d’infra ECS se composent de 3 étapes principales :

3-stage pipeline
Je vais aborder ici uniquement 2 modifications majeures d’un cluster ECS :
- La modification de l’AMI utilisée pour les instances EC2 du cluster (launch configuration) réalisée durant l’étape 2 du pipeline.
- La modification de l’image Docker (task definition) réalisée durant l’étape 3.
3 Prérequis
Pour la bonne compréhension de cet article il est nécessaire d’avoir :
- Une bonne connaissance des services/fonctionnalités AWS : EC2, autoscaling group
- Des notions de base sur la conteneurisation Docker
4 Les concepts clés
Les principales notions qui seront abordées :
| Service | Concepts/fonctionnalités |
| EC2 | Instance type (vCPU & Memory)
Autoscaling group |
| CloudWatch | Metrics
Dimension Alarm |
| ECS | Deployment type
Task definition\memory Task definition\memoryReservation Task definition\PortMappings Service Launch type Service Autoscaling Service scheduling strategy Service Deployment options \ minimum healthy percent & maximum percent |
5 Architecture
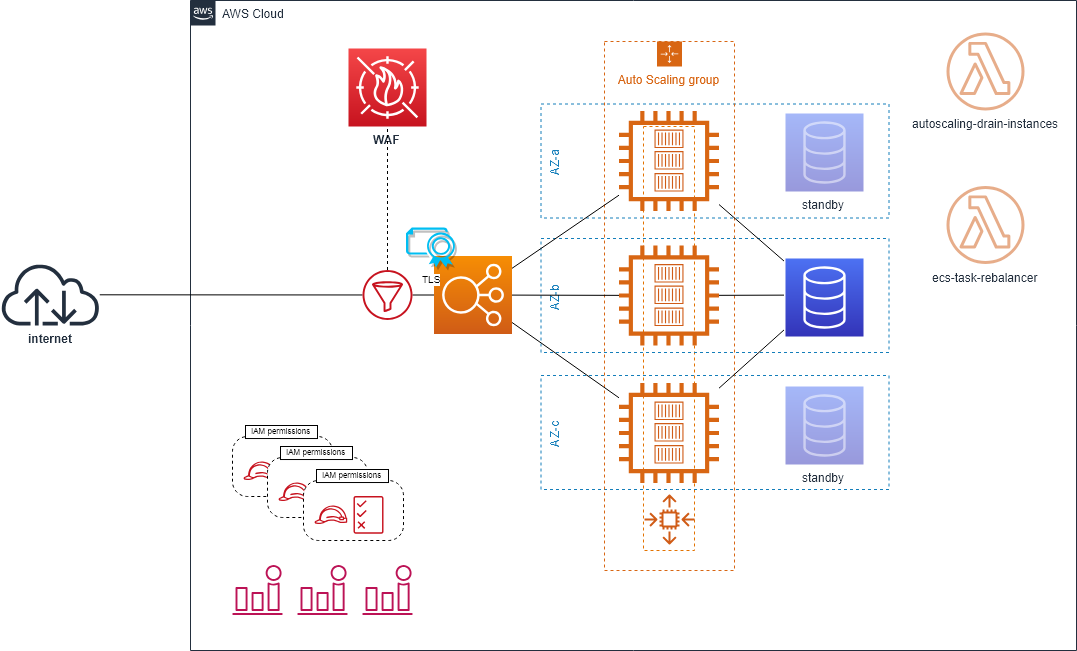
High-available ECS cluster
Ici, le cluster ECS est constitué d’une flotte d’instances EC2 déployées au sein d’un auto scaling group couvrant les 3 zones de disponibilité que compte la région. Le trafic est réparti entre les différents containers à l’aide d’un ALB. Le mappage de port est réalisé de façon dynamique.
Le redimensionnement est réalisé comme suit :
- L’auto scaling applicatif est mis en œuvre au sein d’ECS et assure la scalabilité au niveau des conteneurs
- L’auto scaling groupe EC2 permet quant à lui de modifier le nombre d’instances dans la flotte
Toutes les ressources AWS sont déployées en IaC par le biais de Terraform. Of course !
6 ECS : comment ça marche… en vrai
Les utilisateurs d’ECS en type de lancement EC2, l’ont certainement déjà constaté : la mise à jour d’un cluster ou d’un service ECS n’entraîne pas les actions auxquelles on pourrait s’attendre.
Contrairement à nos attentes, le déploiement d’une nouvelle configuration ne s’opère pas forcément automatiquement et sans interruption de service. Whaaaaaaaaat ?
Dans ce monde où l’on ne jure plus que par le déploiement continu et l’intégration continue, les déploiements doivent s’opérer avec le moins possible voire aucune interaction humaine. Dans un tel environnement, l’interruption de service n’est plus acceptable… ? Alors comment faire pour y arriver avec ECS sans se tourner vers CodeDeploy ???
6.1 Mise à jour de l’AMI
En effet, la mise à jour de l’AMI définie dans la launch configuration d’un auto scaling group entraîne la destruction des instances présentes dans le groupe avant même que les instances basées sur la nouvelle image ne soient opérationnelles. OMG !
Solution :
AWS recommande, depuis 3 ans au moins, d’ajouter une UpdatePolicy à votre groupe Auto Scaling. En bref, cela permet de retarder l’arrêt Auto Scaling d’instances EC2. Ce qui permet d’effectuer une mise à jour par lot de la flotte.
Je ne m’étalerai pas plus sur cette fonctionnalité car ce qui est décrit dans l’article susmentionné est déjà concis et limpide. De plus, nombreux sont les articles et tutos sur le net qui traitent du sujet.
Néanmoins, cette option ne suffit pas à vous prémunir des déconnexions intempestives que pourraient subir les utilisateurs de votre microservice suite à la suppression d’une instance de l’ASG basée sur l’ancienne version de la launch configuration.
Solution additionnelle :
Pour pallier cette lacune, AWS propose depuis 2 ans une solution pour automatiser le mise en mode drain des instances de conteneurs ECS dont voici l’architecture :
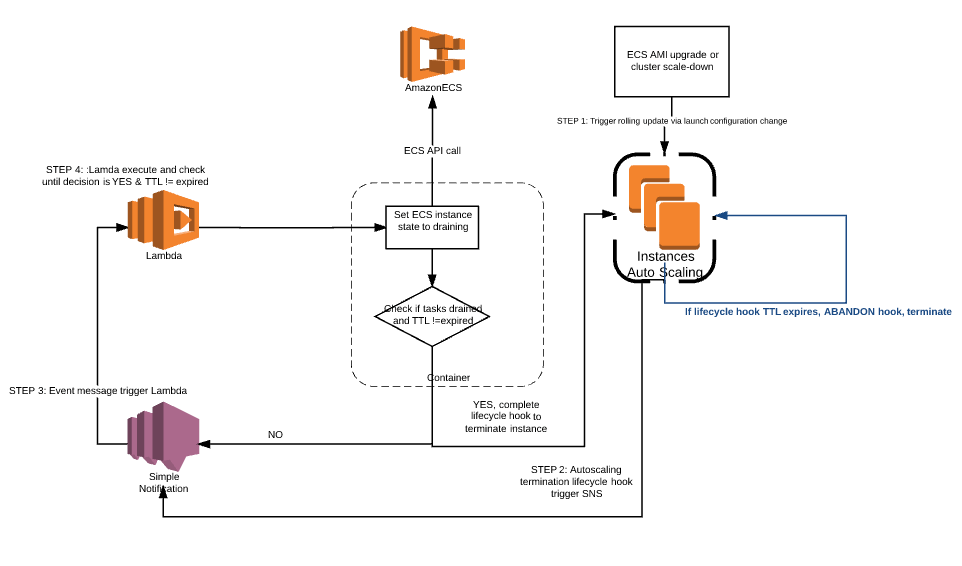
EC2 Auto scaling group drain
Cette solution exploite l’évènement auto scaling : EC2_INSTANCE_TERMINATING de sorte à déclencher l’exécution d’une fonction Lambda qui retarde la suppression des instances concernées. Les instances en question sont au préalable placées en mode DRAIN pendant un certain temps avant que celles-ci ne soient détruites. Les lifecycle hooks constituent la fonctionnalité permettant à la suite d’évènements auto scaling d’exécuter des actions personnalisées comme la mise en attente d’instances EC2 qu’un groupe Auto Scaling lance ou résilie.
6.2 Mise à jour de l’image Docker
ECS en type de lancement EC2 réserve encore une surprise de taille en cas de mise à jour de votre image de conteneur. Aussi surprenant que cela puisse paraître, la modification de la définition de tâche n’entraine pas de rolling update au niveau des conteneurs s’exécutant au sein du cluster ECS si vous n’utilisez pas CodeDeploy… #OhMyGooooooood !
Lors de la mise à jour de la définition de tâche, ECS (Terraform) rend INACTIVE la version précédemment déployée N et celle à déployer N+1 devient la version ACTIVE. Les conteneurs existants et basés sur la version N continueront à s’exécuter et à recevoir du trafic. Les processus de dimensionnement auto scaling des services existants basés sur la version N poursuivront normalement leur cours.
Toutefois, la mise en service de la nouvelle image Docker (N+1) sera dépendante d’un éventuel processus de dimensionnement par augmentation des ressources RAM et/ou CPU disponible au sein du cluster. #OMG once again !
7 La solution
Afin de remplacer CodeDeploy, j’ai donc développé une solution qui se compose en gros de 2 fonctions Lambda et une file d’attente SQS pour parvenir à mes fins.
- La première fonction sert à réaliser l’opération d’ajout d’instance dans l’auto scaling group et de facto dans le cluster ECS. Elle est déclenchée par 2 types d’évènement : ecs:DeregisterTaskDefinition et tous les évènements « Task State Change Events » (OPTIONNEL).
- Une fois l’auto scaling redimensionné, ladite fonction poste dans la file SQS un message ayant un délai retardant sa livraison. Ce délai doit idéalement correspondre à minima au temps nécessaire au démarrage du microservice.
- La seconde fonction quant à elle sert à réaliser l’opération inverse à savoir rétablir le groupe auto scaling à sa taille initiale. Elle est déclenchée à l’expiration du délai de livraison.
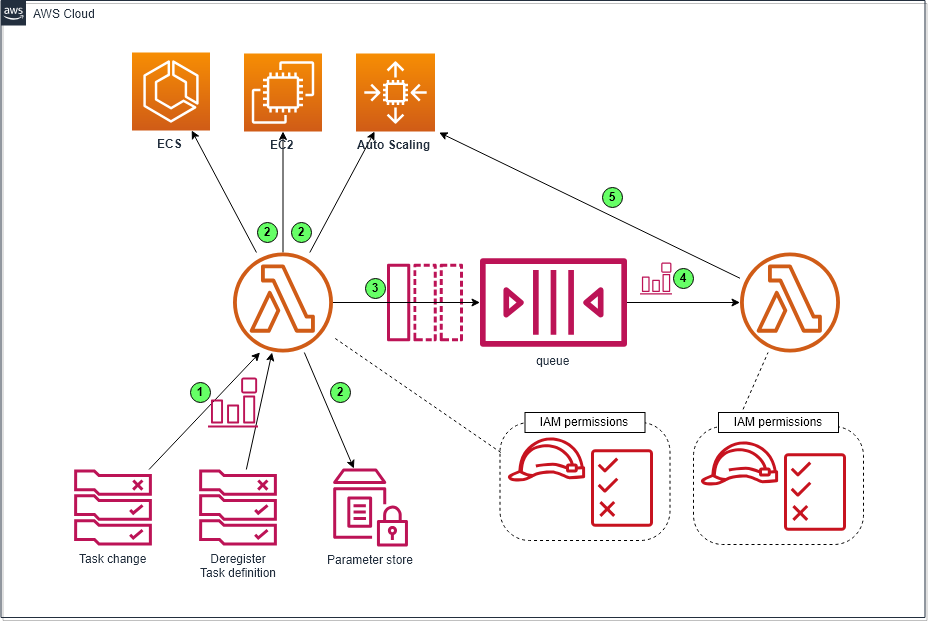
DZ ECS rolling update solution
Plus en détail, des mécanismes de filtre et d’idempotence sont implémentés au sein du code ; le paramètre SSM permet à la fonction d’ajout d’instance de déterminer si un déploiement a déjà été opéré pour la version ACTIVE de la définition de tâche.
Le message SQS contient les infos permettant à la fonction réceptrice d’avoir connaissance des valeurs de MIN, DESIRED et MAX définies pour le groupe auto scaling avant et suite à l’opération de dimensionnement. Les valeurs initiales ne sont rétablies que si les valeurs courantes du groupe correspondent à celles définies suite à l’ajout d’instance.
Les messages générés facilitent le debug de la solution (étape réalisée, ID du message etc. sont logués)

Le code est disponible depuis GitHub.
8 Conclusion
L’offre ECS de base (sans intégration avec CodeDeploy) compte certains avantages mais surtout un inconvénient majeur dans un environnement CI/CD, à savoir l’absence de mise à jour automatique des tâches.
Voici un petit tableau qui traite des pros/cons de la solution alternative à CodeDelploy proposée dans le présent article :
| Points forts ? |
– L’offre gratuite d’AWS couvre largement les coûts de la solution ; Lambda et SQS dispose tous les deux d’une offre gratuite illimitée dans le temps de respectivement 1 million d’exécutions et d’autant de requêtes par mois |
| Points faibles
☹ |
– Absence de Roll back en cas de health check en échec. Ledit roll back peut être implémenté avec du développement supplémentaire.
– La ressource Terraform « aws_ecs_task_definition » est en réalité plutôt traitée comme « aws_ecs_task_definition_revision » et par conséquent toute modification de celle-ci entraine la désactivation la version courante de la tâche définition (deregister-task-definition) et la création d’une nouvelle révision. Cela est expliqué ici. De ce fait, en cas de modification de la définition, aucun roll back vers la version précédente de la définition de tâche n’est en fait possible sans nouveau déploiement. Cela peut aussi être réalisé avec du développement supplémentaire. |
Au sein d’un cluster ECS stable, la mise à jour de la définition de tâche (image Docker par ex.) sans CodeDeploy n’engendre pas automatiquement de déploiement de nouvelles tâches basées sur la nouvelle version de la définition. Pour que de nouvelles tâches basées sur la nouvelle définition soient déployées, il est indispensable que des ressources RAM et/ou CPU supplémentaires soient allouées au cluster, comme cela se produirait quand :
- Au moins une nouvelle instance EC2 est déployée dans l’auto scaling group
- Certaines tâches sont stoppées
Pour y remédier, j’ai donc développé cette alternative low cost à CodeDeploy pour des déploiements en continu.
Bien entendu, cette solution n’est qu’une alternative à CodeDeploy car disons-le CodeDeploy s’intègre parfaitement avec ECS et offre une interface et des fonctionnalités largement suffisantes pour réaliser des rollings updates en blue/green (voir ici).